String Encoding In Django
Status: (as of Friday, June 1, 2007) Documents the UnicodeBranch implementation. -- mtredinnick
Introduction
Django accepts and sends data to and from a number of external entities: databases, web browsers (form input, HTML output), XML syndication feeds, PDF documents... the list is quite long. Since we would like Django to be able to offer all these features to people in all locations, we need to pay particular attention to our internationalization support.
An important part of internationalization is how we handle strings inside Django and at the interfaces between Django and other applications.
This page tries to capture both what we are aiming to do internally. It is partly an attempt to get my (Malcolm Tredinnick's) thoughts down in a logical form. This stuff is very tricky and it's easy to become confused when working on the code. That happens to me regularly, so I need notes like this.
String Types In Python
Python essentially has two different types of strings: bytestrings, which are sequences of 8-bit bytes that can sometimes be printed, and unicode strings, which hold true Unicode character points in a portable fashion. Unicode strings carry no particular byte encoding, but can be converted to any encoding we like, using the encode() method, possibly with the aid of the codecs module in the standard library.
Applications intending to be of use to an international (or even merely non-ASCII) audience are recommended to use unicode strings internally wherever possible. Communication with the outside world (e.g. web browsers) usually involves sending and receiving bytestrings (or streams of data that can be converted to bytestrings) and carrying around information about the encoding of those bytestrings alongside the string. This shows the logic behind using unicode strings wherever possible: without an extra piece of information indicating the encoding, a bytestring is an opaque data item. We have no way of knowing whether the bytes it contains are encoded as UTF-8 or KOI8-R or anything else. So we either have to invent a new object representing a bytestring + encoding or convert to the existing Python solution: unicode strings, which are encoding-neutral.
A lot of this page is concerned with identifying where we cannot avoid bytestrings and how to work out their encoding at that point and then converting them to unicode immediately for internal use.
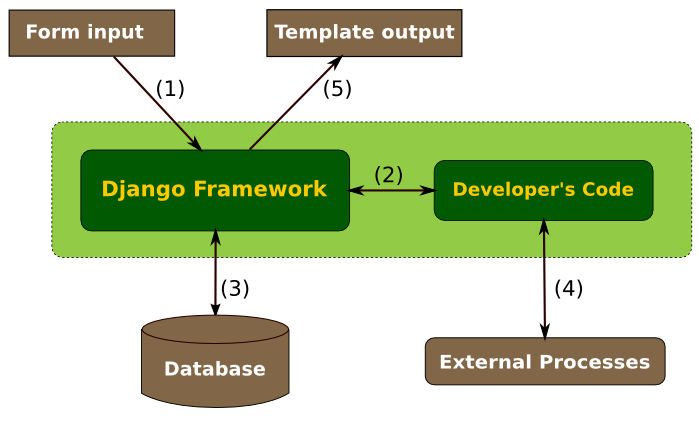
The Big Picture

Each arrow in this diagram shows an interface between the core Django framework (henceforth, Django) and applications which interact with Django. The arrow heads show the direction of the string exchanges.
For simplicity, I have written "Form Input" to represent any kind of data submitted to Django and, similarly, "Template output" to represent all of the possible data that Django can return to a client.
In the following sections, we will go over each of these interfaces in turn. The goal here is to establish what features Django can control and how it should handle things outside its control. A good understanding of these interactions is necessary in order to establish consistent internal string handling behaviour.
HTTP Input Handling
Django's views should be able to handle any data that can be submitted over an HTTP connection. This includes, but is not limited to
- HTML form submissions (both application/x-ww-form-urlencoded and multipart/form-data MIME types).
- XML data, such as Atom Publishing Protocol, other REST-based protocol submissions or even WS-*/SOAP and XML-RPC-based submissions.
- Abitrary binary data encoded with a known MIME type.
Of these submission types, the first one is the one needing the most attention from Django. Arbitrary data submission, which includes the latter two scenarios, need to be handled by the view functions and presumably those view functions will know how to decode the incoming message.
The main thing we need to concerned with from a string encoding perspective is understanding the encoding of the incoming data and the converting it to a known format for subsequent processing.
Form Input Handing
HTML form submission is an area that has traditionally had poor browser compliance with standards and not particularly encompassing standards in the first place. So there are a lot of corner cases involved here. For the most part, though, we can get by with a few simple rules and a couple of conventions ("conventions" meaning that if you don't follow them, anything could, and probably will, happen).
For simplicity and the sanity of developers (both core and third-party), Django adopts a fairly simple policy when it comes to interpreting form input. Form submissions are assumed to be in the DEFAULT_CHARSET setting. However, decoding of the input is only done when the GET and POST attributes on an HttpRequest object are accessed and the decoding is not cached in any way. So the "encoding" attribute on the HttpRequest instance can be changed and this will update the encoding that is assumed when interpreting GET and POST data. File uploads are never decoded in any way, since they are assumed to already be an arbitrary and opaque sequence of bytes.
Notes:
- This is one area where conversion from UTF-8 to unicode may fail, due to malicious or accidental causes. Any invalid input is treated Python's "replace" codecs error handling.
- setting "accept" types on forms makes it the responsibility of the developer to handle. Don't guess.
Passing Strings Between Django and the Developer's Code
(By Developer's code, I mean any code that is part of an application, but not in Django's core. This includes views, model definitions, URL configuration and templates. Anything the Django user is responsible for writing.)
The only potential problem here is when bytestrings are passed between Django and the developer's code. Once again, we have no way of knowing the encoding. Most of the time, the two parties should exchange unicode strings. When bytestrings are passed, we need to have a convention about how these strings are encoded. This is a case where we cannot enforce (at the Python level) any requirement. We can only say "here is what Django expects" and if a developer does not respect this, any errors are their own to deal with.
Convention: All bytestrings used inside the Django core are assumed to be UTF-8 encoded.
Bytestrings passed between the core and the applications should not be dependent on the encoding of the source files they were created in (those files using PEP 263 encoding declarations). PEP 263 does not do anything special to bytestrings. It parses them, but leaves them with their original encoding. That encoding information is lost as soon as the string moves beyond its original source file.
Similarly, we should not make assumptions based on the value of settings.DEFAULT_CHARSET. That setting is for the default output character encoding used by Django. It is designed to be changeable by the application user. If the internal code depended on this setting, the developer would need to change the code whenever the setting changed and two applications written by two developers with different default assumptions would not interact correctly.
Database Interaction
The application developer may not be in control of the basic database configuration. This may require help from a database administrator. Or the application may be built on top of a legacy database. Consequently, it is unreasonable to assume that Django can enforce a particular character set encoding on the database.
Django encodes all strings it sends to the database with the right encoding method. Similarly, all incoming strings are decoded to unicode objects (keeping them as bytestrings would lose the information about the database encoding, which may not always be UTF-8).
Talking To External Processes
A Django developer's code may need to talk to external services or applications to retrieve necessary data.
It is entirely outside the realm of Django to handle the character set encoding and conversion issues here. Rather, the application developer is responsible for ensuring that any strings used by Django are either unicode strings or bytestrings encoded as UTF-8.
HTTP Output
As with input, Django's output possibilities are essentially limitless. However, we can loosely group them into two categories:
- Template generated output
- Arbitrary data sent back by the view.
These two cases could also be called "things we care about" and "things we don't". In the first case, Django itself is responsible for encoding the output in the correct way and passing the HTTP handler a bytestring that can be returned. This conversion will be done using the encoding specified by settings.DEFAULT_CHARSET.
In the second scenario, the developer (of the view) is entirely responsible for encoding the bytestring correctly and setting the right MIME types and, consequently, charset-encoding value for the returned result.
There are a couple of fuzzy, middle-ground areas here. Automated email sending for 404 pages and other admin items is handled by Django. This is treated similarly to template output generation and settings.DEFAULT_CHARSET is used to encode the output.
Attachments (1)
-
django-i18n.png
(43.8 KB
) - added by 19 years ago.
Diagram of string exchanges within Django
{kind=link}
Download all attachments as: .zip