Opened 16 months ago
Closed 4 months ago
#36293 closed Bug (fixed)
GZipMiddleware buffers streaming responses
| Reported by: | huoyinghui | Owned by: | Farhan Ali |
|---|---|---|---|
| Component: | HTTP handling | Version: | dev |
| Severity: | Normal | Keywords: | gzip flush |
| Cc: | Carlton Gibson, Matthew Somerville | Triage Stage: | Ready for checkin |
| Has patch: | yes | Needs documentation: | no |
| Needs tests: | no | Patch needs improvement: | no |
| Easy pickings: | no | UI/UX: | no |
Description (last modified by )
This ticket proposes adding a test to confirm that compress_sequence()
in django.utils.text correctly flushes each chunk during gzip streaming.
The absence of zfile.flush() would cause compressed output to be buffered,
delaying response delivery in streaming contexts. This test uses timed
chunk generation to verify that data is emitted approximately once per second,
indicating that gzip output is non-blocking when flush() is used.
See related PR: https://github.com/django/django/pull/19335
Attachments (2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (25)
comment:1 by , 16 months ago
comment:2 by , 16 months ago
| Description: | modified (diff) |
|---|
comment:3 by , 16 months ago
| Cc: | added |
|---|---|
| Component: | Uncategorized → HTTP handling |
| Keywords: | flush added; blocking removed |
| Resolution: | → needsinfo |
| Status: | new → closed |
| Type: | Uncategorized → New feature |
| Version: | 5.2 → dev |
Hello huoyinghui, thank you for taking the time to create this ticket. Initially your request made sense, but I did some archeology and in fact zfile.flush() was removed in caa3562d5bec1196502352a715a539bdb0f73c2d (while fixing #24242). I can see in your patch how you added a flag to control whether the flushing occurs or not, but I'm not convinced this is the right solution.
We would need some stronger evidence that the lack of flushing is causing any issues with a streamed response. The commit above mentions:
Testing shows without the flush() the buffer is being flushed every 17k or so and compresses the same as if it had been done as a whole string.
I'll close as needsinfo, I'll add as cc a few folks, and edit the ticket title to be more precise. Please reopen when you can provide more evidence via a Django test project for proper assestment. Thank you!
comment:4 by , 16 months ago
| Summary: | Add test to verify non-blocking behavior of compress_sequence() with zfile.flush() → Extend `django.utils.text.compress_sequence()` to optionally flush data written to compressed file |
|---|
follow-ups: 6 8 comment:5 by , 16 months ago
I'd like to see more exploration of solutions in project-space before we add API here in Django. In particular, from the PR, the magic "text/event-stream" restriction here is... well... a little ad hoc.
Better would be to subclass the GZIP middleware, and just skip compression for for SSE responses (presuming events of less than 17kb). Such would be a small number of lines, and quite a simple approach.
comment:6 by , 16 months ago
I hope you can help me make the naming of the code configuration more standardized.
I’ve already resolved this in my own project by subclassing GZipMiddleware to skip compression for responses with Content-Type: text/event-stream. However, I believe this is a common enough use case that it deserves better support at the framework level.
SSE relies on real-time delivery, and buffering caused by gzip (especially under the 17KB threshold) can introduce noticeable latency on the client side. Developers may not immediately realize gzip is the cause, leading to unnecessary debugging time.
It would be helpful if Django could:
- Document this behavior and its impact on SSE;
- Automatically skip compression for text/event-stream responses;
- Or offer a more explicit way to opt-out of compression per response.
Supporting this natively would improve the developer experience and better accommodate streaming use cases.
Here’s my test case:
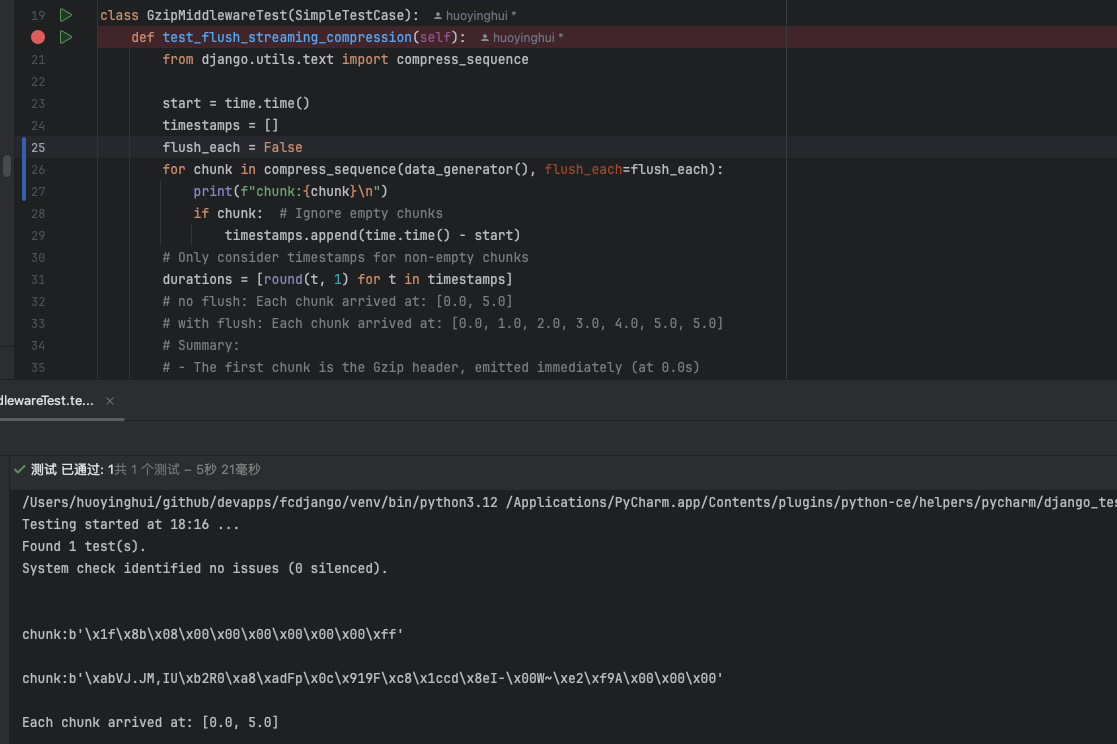
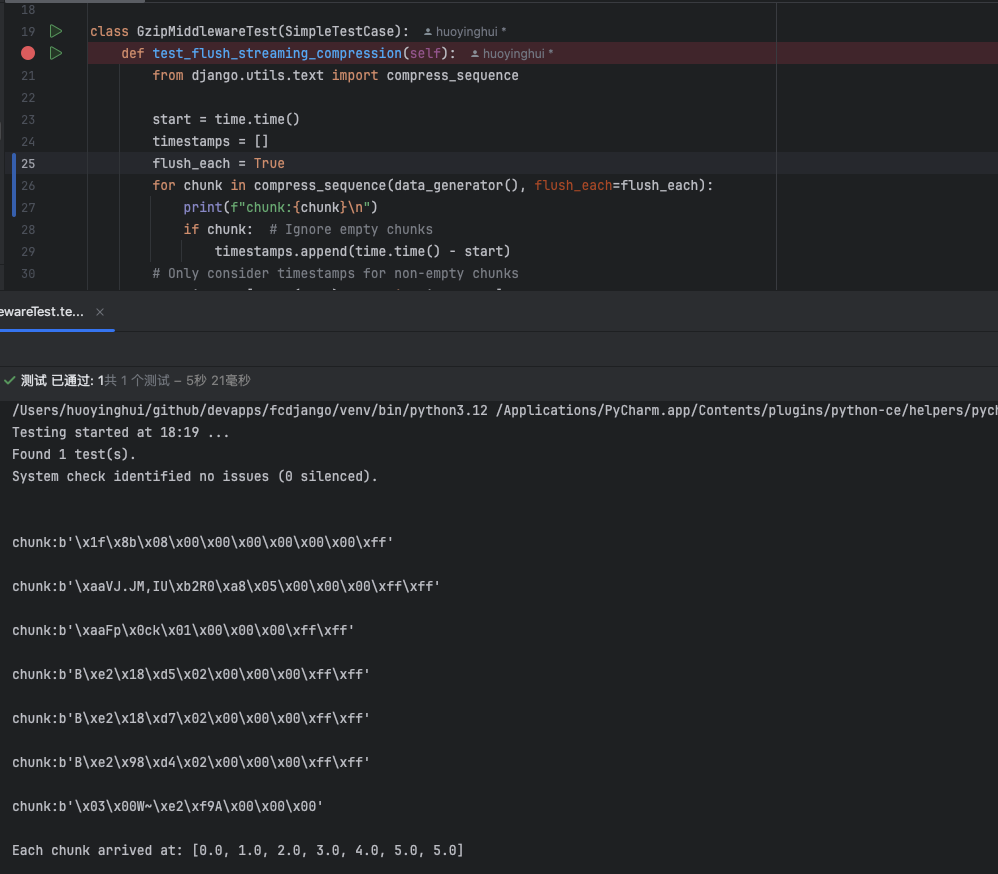
run test in pycharm: tests.middleware.test_gzip.GzipMiddlewareTest.test_flush_streaming_compression
Test results:
- Case 1: flush_each=True
✅ The client receives each event promptly — no visible delay.
- Case 2: flush_each=False (default gzip behavior)
⚠️ All events are buffered and maybe delivered only after ~17KB, which defeats SSE’s purpose. The client appears stuck until buffer threshold is reached.
by , 16 months ago
| Attachment: | image-20250407-181853.png added |
|---|
by , 16 months ago
| Attachment: | image-20250407-181923.png added |
|---|
comment:7 by , 16 months ago
As per the GZip middleware documentation, response content will not be compressed if (among other options):
The response has already set the Content-Encoding header.
You should then be able to set the `identity` content encoding before sending the response to bypass the middleware here.
The RFC has this:
The default (identity) encoding; the use of no transformation whatsoever. This content-coding is used only in the Accept-Encoding header, and SHOULD NOT be used in the Content-Encoding header.
So you might want to strip that header in a subsequent middleware (but compare the MUST in section 14.11)
I think we could consider adding a check here:
# Avoid gzipping if we've already got a content-encoding.
if response.has_header("Content-Encoding"):
# POSSIBLE ADDITION: remove header if response["Content-Encoding"] == "identity" here.
return response
With a line in the docs to make this explicit.
comment:8 by , 16 months ago
Replying to Carlton Gibson:
This is a good suggestion—it’s simple to implement and avoids having the real-time performance of the SSE request blocked by compress_sequence. I accept it.
I think the significance of this issue lies in the fact that when users use Django to develop SSE requests, they may experience sudden blocking. However, it’s not directly caused by their own actions, making it hard to understand and debug.
Perhaps documentation can be added to explain how Django handles SSE responses. To avoid blocking, users need to configure
response["Content-Encoding"] == "identity".
comment:10 by , 9 months ago
I think Natalia got mixed up and meant to report #36655 as a dupe.
In my report there, I demonstrated the issue using HTML, rather than SSE. It could be similarly troublesome to buffer content when streaming HTML, especially if there's time between chunks, such as from database queries.
In fact, I think if you're using StreamingHttpResponse, any buffering from outer layers is unacceptable. It can always be done inside your iterator, if necessary, but once a chunk is ready, Django should pass it out as fast as possible.
#24242 removed the flush() call to reduce the total data transfer. I don't think this was the right call—latency was not discussed at all. The OP also seemed to be using a very naive approach, hooking up a streaming JSON library that yields individual tokens, which sounds like an uncommon way of using StreamingHttpResponse.
So I would say reopen this ticket and revert #24242—no option to flush. That's the approach I effectively implemented in django-http-compression (PR), when I wasn't aware that flush() was ever removed.
comment:11 by , 9 months ago
Thanks for the script in #36655, Adam.
I don't think this was the right call—latency was not discussed at all. The OP also seemed to be using a very naive approach, hooking up a streaming JSON library that yields individual tokens, which sounds like an uncommon way of using StreamingHttpResponse.
It seems reasonable to revert #24242 if that is indeed uncommon and doesn't reintroduce a performance problem -- so long as we don't introduce additional API, see comment:5 -- but I checked our example of streaming a large CSV, and it yields every row, producing a similar problem.
Adjusting your script like this...
#!/usr/bin/env uv run --script # /// script # requires-python = ">=3.14" # dependencies = [ # "django", # ] # /// import csv import os import sys from django.conf import settings from django.core.wsgi import get_wsgi_application from django.http import StreamingHttpResponse from django.urls import path settings.configure( # Dangerous: disable host header validation ALLOWED_HOSTS=["*"], # Use DEBUG=1 to enable debug mode DEBUG=(os.environ.get("DEBUG", "") == "1"), # Make this module the urlconf ROOT_URLCONF=__name__, # Only gzip middleware MIDDLEWARE=[ "django.middleware.gzip.GZipMiddleware", ], ) class Echo: """An object that implements just the write method of the file-like interface. """ def write(self, value): """Write the value by returning it, instead of storing in a buffer.""" return value def some_streaming_csv_view(request): """A view that streams a large CSV file.""" # Generate a sequence of rows. The range is based on the maximum number of # rows that can be handled by a single sheet in most spreadsheet # applications. rows = (["Row {}".format(idx), str(idx)] for idx in range(65536)) pseudo_buffer = Echo() writer = csv.writer(pseudo_buffer) return StreamingHttpResponse( (writer.writerow(row) for row in rows), # Show the response in the browser to more easily measure response. content_type="text/plain; charset=utf-8", # content_type="text/csv", # headers={"Content-Disposition": 'attachment; filename="somefilename.csv"'}, ) urlpatterns = [ path("", some_streaming_csv_view), ] app = get_wsgi_application() if __name__ == "__main__": from django.core.management import execute_from_command_line execute_from_command_line(sys.argv)
...gives:
gzipped, no flushing: 315KB, 194ms gzipped, with flushing: 859KB, 1.5sec no gzipping: 1.09MB, 450ms
In the case of adding flushing the gzipping triples the response time to produce a 10% smaller response.
What do you suggest we do here?
comment:12 by , 9 months ago
…so long as we don't introduce additional API…
Just to clarify, I'm not anti more API here per se. Rather, I'd like to see us be sure we've thought it through before we do that.
I have a pretty strong suspicion that an ounce of docs would go a long way here (especially given the identity encoding suggestion above)
In the case of adding flushing the gzipping triples the response time to produce a 10% smaller response.
I think there's a typo there somewhere. 🤔 (The numbers as written have triple response time for ≈double response size, unless I'm failing to read it right.)
comment:13 by , 9 months ago
(The numbers as written have triple response time for ≈double response size, unless I'm failing to read it right.)
Ah, I was comparing GZipMiddleware + Adam's proposal (859KB) to *no GZIPMiddleware* (1.09MB), so it's about 10% 20% smaller. (This was because in #24242 the ask was "flushing makes the middleware useless in my case", and I wanted to evaluate Adam's suggestion that that was a deviant case.)
comment:14 by , 9 months ago
Thanks for using that example Jacob.
However, I don’t think it’s a great template for streaming responses, pushing one line at a time. The approach is quite wasteful for HTTP, as each line is pushed in its own packet. Moreover, it would be wasteful to load one record at a time from the database.
A better example would paginate a queryset and yield one page of rows at a time. This would be more optimal in all layers, compression included. And this should stnad for streaming all kinds of data: HTML, JSON, CSV, ...
I modified the example to send batches of 100 rows at a time using itertools.batched:
#!/usr/bin/env uv run --script # /// script # requires-python = ">=3.14" # dependencies = [ # "django", # ] # # [tool.uv.sources] # django = { path = "../../../django", editable = true } # /// from __future__ import annotations import csv import os import sys from io import StringIO from itertools import batched from django.conf import settings from django.core.wsgi import get_wsgi_application from django.http import StreamingHttpResponse from django.urls import path settings.configure( # Dangerous: disable host header validation ALLOWED_HOSTS=["*"], # Use DEBUG=1 to enable debug mode DEBUG=(os.environ.get("DEBUG", "") == "1"), # Make this module the urlconf ROOT_URLCONF=__name__, # Only gzip middleware MIDDLEWARE=[ "django.middleware.gzip.GZipMiddleware", ], ) def some_streaming_csv_view(request): """A view that streams a large CSV file.""" # Generate a sequence of rows. The range is based on the maximum number of # rows that can be handled by a single sheet in most spreadsheet # applications. rows = ([f"Row {idx}", str(idx)] for idx in range(65536)) buffer = StringIO() writer = csv.writer(buffer) def stream_rows(): for batch in batched(rows, 100): buffer.seek(0) buffer.truncate() writer.writerows(batch) yield buffer.getvalue() return StreamingHttpResponse( stream_rows(), # Show the response in the browser to more easily measure response. content_type="text/plain; charset=utf-8", # content_type="text/csv", # headers={"Content-Disposition": 'attachment; filename="somefilename.csv"'}, ) urlpatterns = [ path("", some_streaming_csv_view), ] app = get_wsgi_application() if __name__ == "__main__": from django.core.management import execute_from_command_line execute_from_command_line(sys.argv)
(Note editable Django install in metadata, needs correct path.)
I used this cURL command to measure the same stats you were checking:
curl -w "%{size_download} %{time_total}" -o /dev/null -s -H "Accept-Encoding: gzip" --raw "http://127.0.0.1:8000/" | awk '{printf "%.0fKB, %.0fms\n", $1/1024, $2*1000}'
It gave me these results:
gzipped, no flushing: 307KB, 44ms
gzipped, flushing: 287KB, 52ms
no gzipping: 1066KB, 30ms
This change makes the flushing version *more* optimal than the flushless one (73% savings versus 71%), while a bit (~15%) slower. I think we can always expect some slowdown because we’ll send more packets, but the per-chunk latency saving is worth it.
So maybe we should rewrite that example, as well as restore the flushing?
comment:15 by , 9 months ago
| Has patch: | unset |
|---|---|
| Summary: | Extend `django.utils.text.compress_sequence()` to optionally flush data written to compressed file → GZipMiddleware buffers streaming responses |
| Triage Stage: | Unreviewed → Accepted |
| Type: | New feature → Bug |
So maybe we should rewrite that example, as well as restore the flushing?
Sounds reasonable to me. The docs suggestion from comment:5 seems like settling for less, since we'd be giving up the ability to compress streaming responses, but I'm open to anything I've missed.
comment:16 by , 9 months ago
| Resolution: | needsinfo |
|---|---|
| Status: | closed → new |
comment:17 by , 8 months ago
| Owner: | set to |
|---|---|
| Status: | new → assigned |
comment:18 by , 7 months ago
| Has patch: | set |
|---|
comment:19 by , 7 months ago
https://github.com/django/django/pull/20401
I opened this pr for this.
I added zfile.flush() and updated the example to use batching, which may prevent the issue with response size.
comment:20 by , 5 months ago
| Needs tests: | set |
|---|---|
| Patch needs improvement: | set |
comment:22 by , 5 months ago
| Needs tests: | unset |
|---|---|
| Triage Stage: | Accepted → Ready for checkin |
https://github.com/django/django/pull/19335